First, important dates:
- 2008-09-11: We have the deca-hose from here, with a higher % of the tweets at the beginning and down to 10% now (with the total volume increasing greatly over that time). Geo is (was) roughly 1% of all tweets, first with a "coordinates" and then with the "places" field.
- 2009-11-11: The first geo-tweet we have on the books is here:
gzip -cd zipped-raw/2009-11-11/2009-11-11-11-15.gz | less - 2014-03-07-13-53: turned the spritzer to filter for geo tweets, pulling ~3000K per minute. Some small fraction of these didn't have a lat/lon, just had a "location”, this was about 10%. Around this time, there were ~850 geo tweets (lat/lon) per minute coming in from the gardenhose.
- 2014-04-14: twitter upgraded their backend and we starting getting 7-10K geo tweets per minute from the spritzer.
- Unknown dates: There have been various outages of the geo spritzer over the past two years, but we have most of it, I think (why aren't we running 3 of them?)
- Unknown date: At some point, the overall volume slowed back down to 3K/minute from the geo spritzer
- 2016-12-07: Data change from Gardenhose to GNIP decahose
Other
- There is a database living at UVM that Morgan built to store the geo tweets starting in 2011 in SQL...it got really big despite UVM saying they could handle it, I don’t know how to use this database
- Morgan: This seems correct to me. SQL was a fine solution the first year we used it for the geotagged tweets, but appears to be woefully insufficient with the current magnitude of data. One reason for this is that SQL scales vertically (i.e. with faster machines) rather than horizontally (i.e. with parallelization). Hadoop is an example that benefits from horizontal scaling, but there are others. With a beautiful tool like the VACC already in place, it seems to me that horizontal scaling is a viable option.
- SSH to bluemoon server
- `mysql -u mrfrank -p -h webdb-large1.uvm.edu -e "use MRFRANK_2; INSERT SQL COMMANDS HERE!!!!!"``
- you will need password, ask Morgan
- Jake build a geo database that pre-processed each tweet to place it in hierarchical boxes by country/state/county (us-analogy, these are more general) and accessed by the incredibly reliable
pullTweets.plscript (it's txt files for each minute stored in folders by location, all zipped up, that can be searched through without unzipping it to disk). With the decline in volume, I think that this stopped happening about a month ago, and the database isn't being updated (I could very well be wrong).
FAQ
- Twitter says that if you pull two geo streams, they will be the same tweets (should we check? may be able to get more data by running two streams with different bounding boxes... also the speed of the scraper may matter (ruby chugger seems to be at least as fast as anything I could write in python)). how similar at the geo tweets from the spritzer and the gardenhose?
- Jake: I did a few tests re: volumes and multiple streams/filters a little while back and am sorry to report that (1) two (spritzer) streams running simultaneously off of the same access key produce nearly identical data (I have not acutely quantified this, but just ran a quick diff---one or two tweets were different), and (2) two disjoint hemisphere streams collectively produce the same volume as one global stream.
- The new tweets are mostly "places" tweets, and lat/lon is going away. Probably related to some business decision by twitter to integrate with foursquare (which they have), but where does this leave us?
- How reliable are the "places"? If there is also lat/lon in the tweet, do they generally agree?
- Are there tweets with both lat/lon and “places” specified?
- Yes, though it is a small fraction of the overall stream.
- Do the tweets we’re currently collecting include the “places” specified tweets?
- Yes.
- Am I right in assuming that the spritzer has a filter set for locations?
- Yes, it is the bounding box for the whole world.
Other observations
- Jake: As long as 10% of all tweets are tagged with some form of location, then application of the same filter to the garden hose will not result in reduced volume there. Presumably we could estimate the current proportion of tweets tagged with location from the spritzer, but Twitter seems to be pretty tight-lipped about their sampling methods: https://twittercommunity.com/t/is-the-sample-streaming-api-truly-random/14942
- Jake, Re accuracy: My assumption is that the 'places' are reasonably accurate. It appears that they default to a detected location (once enabled), and my guess would be that most folks don't spend too much time switching locations for each tweet. However, even if this data is good, there will forever be a new cohort of data doubters who fear duplicitous behavior.
If we find that the centroids for the "places" are close to the exact geo location, we can start using those for the pullTweets database.
Analysis of "places" Tweets
Okay so here are the most recent numbers. these are the fields that we're looking for:
tweet["coordinates"] (ref: https://dev.twitter.com/overview/api/tweets#obj-coordinates)
tweet["geo"] --- this was the old place for coordinates
tweet["place"] (ref: https://dev.twitter.com/overview/api/places)
I did a parse for:
- tweets that contain any of them: "any".
- tweets that contain the coordinate field: "coordinates”;
- tweets that contain only the coordinates field: "coordinates-only”.
- tweets that contain only the places field: "place-only".
Did this for both the spritzer and the main stream, here are the numbers from wc (the first number is the count of Tweets):
2016-02-15-00-00-any.gz
7815 305189 23191117
2016-02-15-00-00-any-spritzer.gz
43128 1679248 127526514
2016-02-15-00-00-coordinates.gz
1029 37231 2942433
2016-02-15-00-00-coordinates-only.gz
5 180 11608
2016-02-15-00-00-coordinates-only-spritzer.gz
30 773 69684
2016-02-15-00-00-coordinates-spritzer.gz
5655 207164 16125655
2016-02-15-00-00-place-only.gz
6786 267958 20248684
2016-02-15-00-00-place-only-spritzer.gz
37473 1472084 111400859
Total in the spritzer is 46643 and total in the 10% feed is 398616.
Observations
- there are 3K tweets on the spritzer that have none of these? what's up with those?
- VERY few (effectively none) have only the coordinates (likely folks using an out-of-date version of the Twitter app).
- close to a 6X boost for all categories on the spritzer.
- 13% of the tweets with "place" also have "coordinates".
- we're still getting the same number of coordinates tweets from the spritzer as total geo tweets (place or coords) from the 10% stream.
- 1.9% of tweets in the main stream have "any": we can then estimate that there are 78K total "any" tweets. we're only seeing 43K of these on the spritzer. so either we're still missing some (almost half) on the spritzer, or the 10% over-samples the geo.
How good is the center of bounding boxes?
Next, I'll see how close the the place is to the coordinates for that subset.
So 6455 of the 6473 tweets that I tested (almost all) were inside the bounding box, with a mean distance of 52km from the centroid.
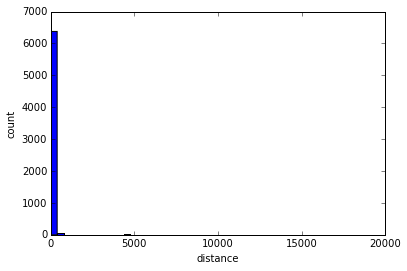
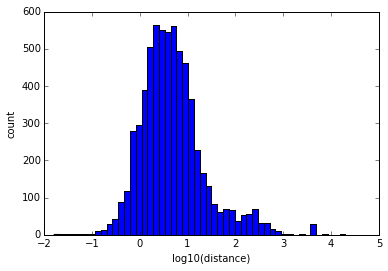
What the distances from the centroid look like. (note: everything in kilometers)
- Tell me, what does “bounding box” mean in this context
if the centroid is 52km from the tweet? Is it a county?
- I think that these "places" are all sorts of things. Farrell Hall is one, so is the city of Burlington, so is the United States. Each place just comes with 4 points to describe it, and most of the points are within that bounding box. We could query more details on the place from Twitter's API, which I think is a more detailed geo fence than the bounding box.
More next steps
- Use data for a longer timeframe (this is only 15 minutes worth).
- Look at the outlier tweets...
- Bin by the size of the bounding box (a USA box is likely to have a tweet further from the centroid), maybe small bounding boxes are most useful for the location?
- Cross reference the place database with the retail store locations (download their place database?).
Maybe these will be useful for specific projects, and we can test the tweet data as necessary.
Final thoughts
The statements that 13% of the tweets with "place" also have "coordinates" and 1.9% of tweets in the main stream have “any" indicate that the coordinate-tagged tweets alone now comprise a meager 0.2% of the stream in general (i.e., a drop from ~1%)?. Twitter made it harder to geo-locate with GPS when they integrated with FourSquare.
The policy decision by Twitter to allow for the soft 'place' location (and its adoption by users) has watered down the data that Twitter is collecting from its users!